
Blog
Java Statistical Libraries This is a simple post listing a few of the Java statistical libraries I have used at one point or another. Google often seems to fail me when searching for libraries like these so I am hoping that this will help a few people to connect up with these useful libraries. This is just a list of the libraries I have used, I am sure it is not comprehensive.
RunBash: Execute Real Shell Commands from Groovy RunBash
This post is about running shell commands from within Groovy, specifically bash but it is easy to adapt to other shells. Groovy has built-in support for running commands like this:
OnlineTable: Class to access csv files one row at a time by named columns. ####OnlineTable
Cytoscape Scripting with Groovy Cytoscape is a network analysis package used quite often in systems biology. Cytoscape has scripting support for Python, Ruby, and Groovy. Or at least they say there is scripting support for Groovy, but there wasn’t a meaningful Groovy example that I could find. So I made a couple of minor changes to the Ruby example, along with logging added for debugging and, behold, an example Cytoscape Groovy script:
viewtab: A Fast Big Data Spreadsheet viewtab
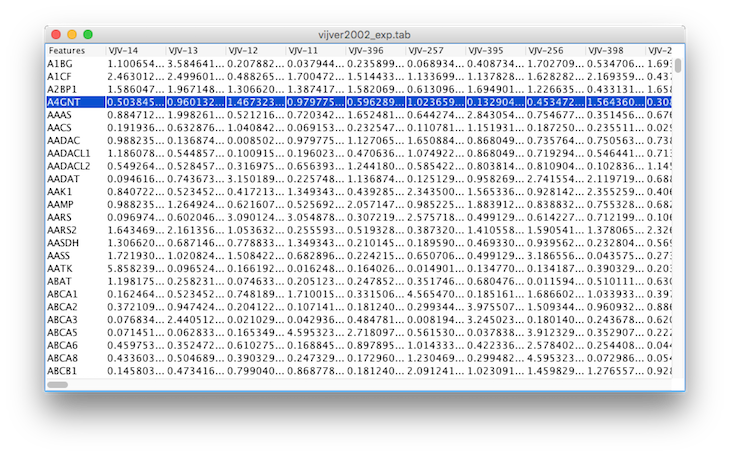 In a previous post I showed
In a previous post I showed csvsqlwhich is one program in my arsenel of TSV/CSV file handling tools. Today’s post highlights another tool,viewtab, which is a fast read-only spreadsheet for exploring data in tab files. I often get data files from scientists or from the supplements of journal papers with only a vague clue what is in the file. I cancatthe file but if the file has many columns a simple cat quickly becomes illegible. There are fancier things you can do withcatsuch as:Tooltip for HTML5 canvas written with Processing.js The visualization code I’m writing using Processing.js needs a tooltip to display some information depending on where your mouse is in the canvas. Although there are many tooltip options for webpage elements, I didn’t find any that I could easily use with Processing.js to generate tooltips dependent on the mouse position in the canvas. After a few frustrating attempts with various libraries I finally just took this rounded corners demo by F1LT3R. and hacked together a ToolTip class of my own that works with Processing.js. I think it’s pretty nice for a quick hack.
Processing.js First Impression I’ve been playing around with Processing.js to produce visualizations of some genomics data. The Java based Processing language/environment was originally developed by the noted data visualization guru Ben Fry and graphic artist Casey Reas. Processing.js is a port of the Processing language and libraries to javascript and the HTML 5 canvas by none other than John Resig, the creator of the jQuery javascript library. I was skeptical at first that Processing.js would be anything but a pale shadow of it’s Processing predecessor, but after using it for a bit I have to say that I am impressed. Most of the Processing sketches one can find scattered around the web and on such sites as Open Processing just work. Here, for example, is a sketch from the examples on Processing.org called reflection2.
Gibbs sampler in Groovy I recently read a couple of nice articles by Darren Wilkinson about implementing MCMC in various languages. The posts are here and here. Wilkinson apparently uses, or is considering using, Python for a lot of prototyping and C for a lot of his actual MCMC runs. However, since he feels that Java is in some ways nicer than C, and almost as fast, he has been using Java for some of the final MCMC runs. I thought I’d see how Groovy performed on this task.
Using Groovlets in jQuery tutorial I’ve been learning a little about jQuery by going through the excellent jQuery tutorial over at the jQuery Docs page. The examples use
PHPfor server side code, but since I’m more familiar with Servlets/Groovlets, I decided do the server side code as a Groovlet.csvsql: A script to perform database queries on csv files. ##About csvsql is a command line script that treates csv and tsv files as database tables. csvsql allows you to perform arbitrary queries on those files, including multi-file joins. The core functionality is provided by the h2 database engine. csvsql itself is written in Groovy, but is simply run like like any command-line program.
Executing SQL on CSV Files in Groovy My life is full of comma separated value files. A common occurrence is to be given a csv file of data and want to explore it a little bit to see what is there, or to extract several columns of data out of the csv file and create a new csv file, or grab only certain columns of data and certain rows of data and create a new csv file. Quite often I find that I even need to join one csv file with another csv file. Each time I’m faced with this task I find that what I want is to do execute sql statements on the csv file itself. After ages of writing one-off scripts to process files like these, I finally looked into actually treating csv files as databases. It turns out that the h2 database engine has good support for both in-memory databases and csv file importing. With Groovy, it’s very nice. Simply download the h2 database jar and drop it in your
~/.groovy/lib/ directory. Then you can write code like this:Create/open OmniOutliner notebooks from command line I like to use OmniOutliner as a lab notebook, and I like to be able to create/open notebooks from the command line. The OS X ‘open’ command will open an existing file, but I didn’t see any obvious way to run OmniOutliner from the command line and tell it to create a new file. So I created an empty OmniOutliner file and dropped in ~/Documents/template, then wrote a little script to copy that template and open it if it doesn’t exist, or open the pre-existing file if it does. Simple and effective.
Weka: getting predictions from cross validation A common question in Weka forums is how to keep track of instances with names. Weka does not have a name field for instances, so to keep track of instances one has to create a string ID attribute that has the name of each instance. The catch, though, is that most classifiers don’t work with string attributes, and you wouldn’t want to classify on the ID anyway. The official solution then is to delete the ID attribute before calling the classifier. Of course, if you delete the ID, you loose the names for your instances! Oof! One solution is to use the meta.FilteredClassifier classifier with the RemoveType filter as the filter. When you hand a FilteredClassifier off to Evaluation, it will apply the filter before sending it to the classifier, but will keep track of the relationship between the source Instances (with the ID) and the filtered set sent to the classifier. Great. Now what if you want to know how instances were classified during your cross-validation? The API for extracting those classifications is not obvious, but it’s easy enough once you know where to look. In Evaluate.crossValidateModel() you pass in a StringBuffer to hold the predictions. This can then be parsed to obtain the predictions and the instance names they go with. Source code to do this below:
Groovy Compared to Other Scripting Languages If you are a bioinformatics person considering taking up Groovy as an alternative to Python (or Perl or Ruby, etc.), you will naturally wonder how the two compare on a range of simple tasks. Luckily, there is a great set of examples over at PLEAC (Programming Language Examples Alike Cookbook). Most bioinformatics Perl programmers have probably seen the Perl Cookbook by Tom Christiansen & Nathan Torkington. The aim of PLEAC is to implement all of the solutions found in the Perl Cookbook in other languages. The Groovy examples are 100% complete, so you can see how every Perl cookbook solution could be performed in Groovy. Most of the cookbook solutions have also been implemented for Python, which is a more current alternative. Go have a look!
Create/open OmniOutliner notebooks from command line Invalid duplicate class definition…One of the classes is a explicit generated class using the class statement, the other is a class generated from the script body based on the file name. Solutions are to change the file name or to change the class name.
Groovy is Java Groovy is groovy. At least for me. Groovy is also Java. A kind of quick and dirty Java all dripping with syntatic sugar. If you know Java you essentially know 80% of what there is to know about Groovy because underneath it’s all Java objects and the syntax is roughly a superset of Java. Most Java programs will run, unaltered, as Groovy programs. Although Groovy’s dynamic features, powerful language constructs, and other goodness will grow on you, a Java programmer can approach Groovy initially as if it were simply a kind of Java that can be executed without compiling and with the option to soft focus some of the details.